Memoization in HMPL
In version 2.1.3, among other things, new functionality was introduced to improve the performance of sites using hmpl.js.
Query memoization is one of the most excellent ways to optimize programming. “What is it and how does it work?” - I will try to answer these questions in this article.
The concept of memoization
Before proceeding to the consideration of a specific functional, let’s first consider this concept in programming in general.
Memoization is the preservation of the results of the execution of functions to prevent repeated calculations. This is one of the optimization methods used to increase the speed of execution of computer programs.
Before calling the function, it is checked whether the function has been called before:
if it was not called, then the function is called, and the result of its execution is saved;
if called, the saved result is used.
An example of memoization in JavaScript can be the following code:
// Before the introduction of mechanization
const reverseText = (string) => {
const len = string.length;
let reversedText = new Array();
let j = 0;
for (let i = len - 1; i >= 0; i--) {
reversedText[j] = string[i];
j++;
}
return reversedText.join("");
};
const a = reverseText("a123"); // The cycle is running
const b = reverseText("a123"); // The cycle is running
// After the introduction of memoization
const memoizeFn = (fn) => {
const cache = {};
return (string) => {
if (string in cache) return cache[string];
return (cache[string] = fn(string));
};
};
const memoizedReverseText = memoizeFn(reverseText);
const a = memoizedReverseText("a123"); // The cycle is running
const b = memoizedReverseText("a123"); // The cycle does not work
We create a wrapper (a higher-order function) over an already existing function that adds some kind of state, designated cache. The cache stores the arguments and, accordingly, the values obtained from the function. By the key, if it is equal to the input argument, it is already possible to get the finished result in the object without turning the string over again.
This is the basis on which all optimization is based. It’s trivial, we don’t repeat the code again, but only take the already calculated value.
Also, the object was named cache for a reason. The cache is an intermediate buffer with quick access to it, containing information that can be requested with the highest probability.
Here you can already recall the memory that is located between the processor and RAM, but this is clearly a slightly different story.
In general, memoization is widely used in software, which makes it an excellent way to quickly speed up a particular code execution. But this method has its disadvantages, of course.
The main disadvantage, of course, is the extra allocation of memory for storing the results. If a function is executed once, then there is simply no point in memorizing its return values.
Memoization in HMPL
Since HTML is a template language for displaying the user interface from the server to the client, http requests will need to be memorized. Accordingly, the intended result will be the preservation of HTML markup. Here is an example of how HMPL works:
const newDiv = compile(
`<div>
<button>Get the square root of 256</button>
<div>{{ src: "/api/getTheSquareRootOf256", after: "click:button" }}</div>
</div>`
)().response;
According to the event listener on the button, it is obvious that a request to the server can be sent any number of times, but the square root of 256 was 16, so it will be, so the request, theoretically, will come the same.
So, the problem with previous versions is that a new element was constantly put on each request, even if the response from the request is the same.
Specifically to optimize this process, an additional field was introduced, which is called memo.
const newDiv = compile(
`<div>
<button>Get the square root of 256</button>
<div>{{ src: "/api/getTheSquareRootOf256", memo:true, after: "click:button" }}</div>
</div>`
)().response;
It takes the value true or false. It only works for request objects that are theoretically repeatedly sent.
A small diagram has been created to visually display the process:
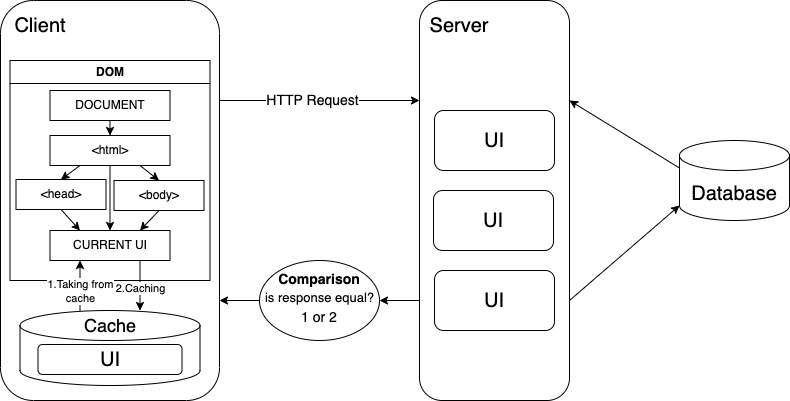
Here, too, the concept of a cache appears, which has already been used before. Also, if we take HTTP requests, then additional concepts of fresh and state response, revalidation, etc. are considered. This all comes from the HTTP cache theory. This point is discussed in more detail in the msdn documentation here. An analogy can be drawn that memoization in HMPL is logically comparable to the no-cache value of the caching mode.
An example of hmpl working without memoization and with it in the DOM:
Without memoization:

With memoization:

During the test, the button to get the user interface from the server was actively pressed.
In one case, we constantly replace the div with a new one, although the response from the server comes the same, in the other, we keep the same element, but only if the responses are the same.
Memoization for file types with the .hmpl extension
Also, memoization will be available not only for one query object, but also for all objects obtained from the compile function with the memo option enabled:
const templateFn = hmpl.compile(
`{
{
"src":"/api/test"
}
}`,
{
memo: true,
}
);
const elementObj1 = templateFn();
const elementObj2 = templateFn();
It will not interfere in any way with other request objects that are triggered only once.
Since the hmpl-loader is based on the compile function, an option will soon be added in which it will be possible to enable memoization for all files with the extension .hmpl:
module.exports = {
module: {
rules: [
{
test: /\.hmpl$/i,
use: [{ loader: "hmpl-loader", options: { memo: true } }],
},
],
},
};
Thank you all so much for reading this article!
P.S. More changes that have been made to the new version 2.1.3 can be found here.